
自作PC環境でAI画像作成が簡単にできる時代になってきました。
私のように絵心がない人間でもうまく言葉を組み合わせることで写真と見間違えるような画像やアニメ絵を作ることができ、また色々な設定を試していくのが本当に面白くてハマっています。
今回は私がやり方を忘れないようにするための備忘録の目的を含め、手始めにまずPCへの「Stable Diffusion」をWeb UI(Automatic1111)で使用する初期設定とスタンダードな画像抽出までをこの記事に書いていきます。
※Windows11環境での導入例を紹介しています。
PC環境の確認
▶冒頭からいきなりですが、AI画像作成するには手持ちのPC環境がある程度整っていないと満足に生成できません。
具体的にはグラフィックボードは必須です。
この記事ではグラフィックボードが搭載されているPC環境があることを前提として、導入する手順から簡単な画像生成ができるまでの紹介をします。
とりあえず自分のPCにグラフィックボードがあるという方であれば、まずはAI画像生成で遊んでみてから面白そうだな、もっとやってみたいなと思った段階で新しいグラフィックボードの購入検討すれば良いと思います。
PCの性能、特にグラフィックボードの性能で画像の生成スピードに大きく差が出ますので、ミドルクラス以上、かつグラフィックボードのビデオメモリが多いほどAI画像の生成に適しています。
まず手軽に始めてみよう、という方にはNVIDIA GeForce RTX3060が比較的安価でおすすめです。このグラフィックボードはビデオメモリが12GBあり、ゲーム用途としてもそこそこの性能を持っています。GeForce RTX4000シリーズが出回りはじめRTX3000のシリーズは旧世代になりますが性能もよく、販売価格も一時期に比べ随分安価になりました。
ゲームもたくさんやるし、AIでガンガン画像生成したいという人にはハイエンドのグラフィックボードを導入するのもありです。例えばGeForce RTX4080 16GBは画像生成は高速ですが18万~と高価です。
なお、私はGeForce RTX4070 12GBのグラフィックボードで主に画像生成をしています。
理想を言えばGPUメモリは8GB以上は欲しいですが、私の手持ちのサブPCのゲーミングノート(GeForce RTX3060 laptop 6GB)でも画像生成は十分可能なレベルでした。
インストール手順
Pythonをダウンロード
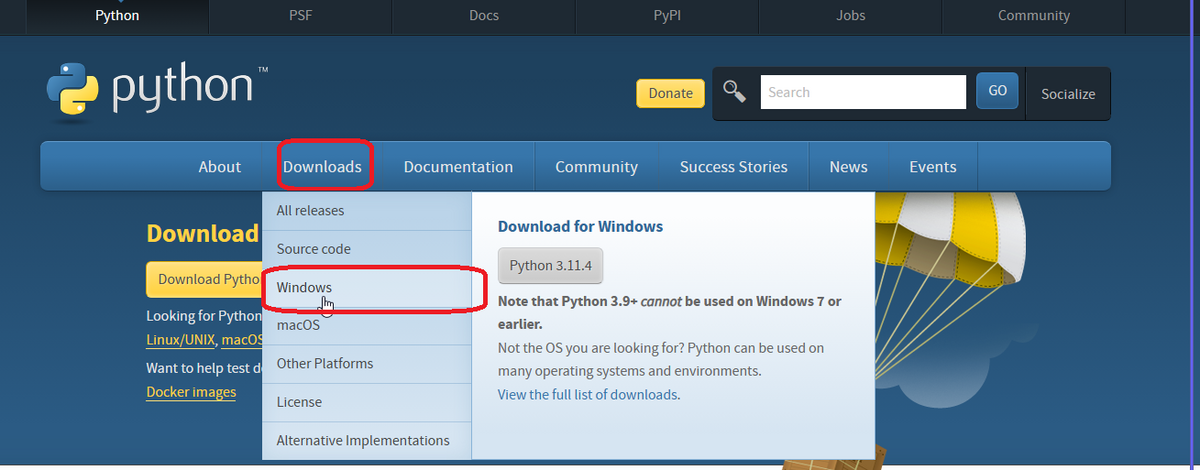
▶色々バージョンがありますが、Stable Diffusion Web UIの公式サイトに対応バージョンが書かれていますので、その通りPython 3.10.6をダウンロードします。
(6/15現在私の環境では3.10.9のバージョンを使って安定していますので、3.10.9でも問題ないと思います)

▶Download Windows installer (64-bit)をクリックしてダウンロードします。

▶なお、なぜPythonを入れる必要があるの?というような技術的な事はここでは書きません。他に詳しいサイト様が沢山あると思うのでそちらを参考にしてください。(というか私も理解していません)
Pythonをインストール
ダウンロードした「python-3.10.6-amd64.exe」を実行します。
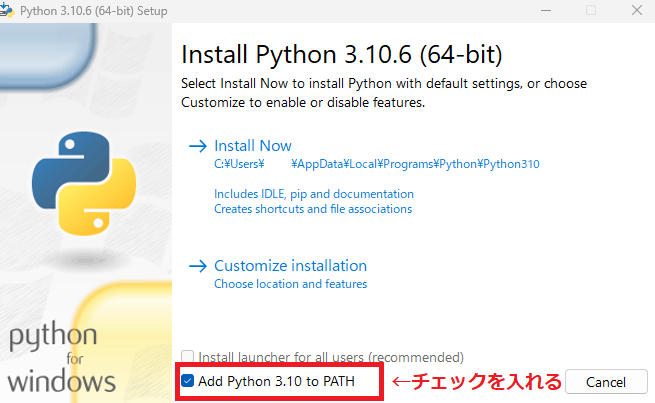
▶赤で囲った部分Add Python 3.10.6 to PATH に必ずチェックを入れてから、Install Nowをクリックしてください。
▶インストールが終わったらCloseで閉じます。
Gitをダウンロード
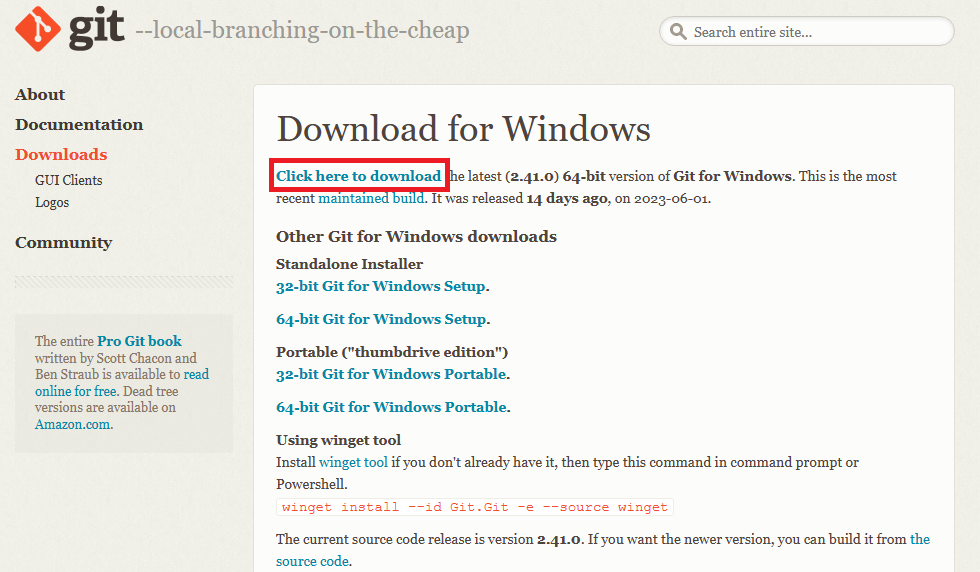
公式サイトからGitをダウンロードします。▶赤で囲った部分をクリックするとWindows版64bitの最新バージョンのダウンロードが始まります。
Gitをインストール
▶ダウンロードした「Git-2.40.1-64-bit.exe」を実行します。
▶インストールの際はこのように沢山色々出てきますが、全てNEXTをクリックでインストールが進みます。
Web UI(AUTOMATIC1111)のダウンロード
▶gitを実行し、Web UI(AUTOMATIC1111)をダウンロード、インストールしていきます。
Web UI(AUTOMATIC1111)をインストールしたい場所を選びます。
日本語のパスがある場所だとうまく動作しない事があるので、Dドライブの直下などを選んでください。
私はOSが入っているCドライブは避け、AI専用のSSD(256GB)を用意してその直下にインストールしました。
ここはAI画像生成の作業フォルダになります。デフォルトでインストールすると約10GB使います。
今後追加することになるモデルファイルは数GB単位の大きなデータとなりますので容量に余裕があるドライブを用意することをお勧めします。
▶インストールしたいフォルダが決まったらフォルダの何もないところで右クリック→Git Bash Hereをクリックします。
※Windows11の場合「その他のオプションを表示」を一度クリックします。
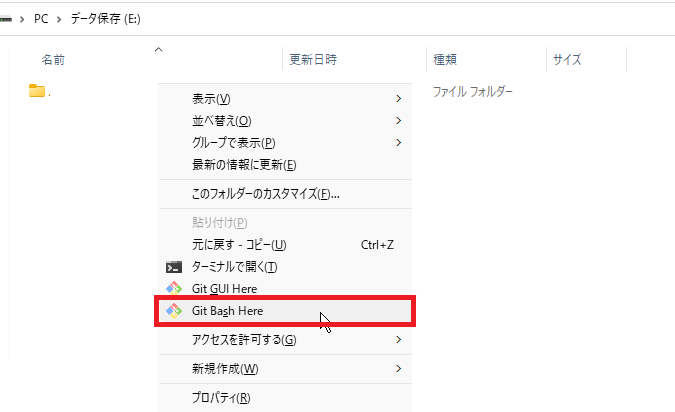
▶画像のようなコマンドプロンプトのような画面が開きます。
以下をコピーし、右クリック→Pasteで貼り付けてください。(ctrl+Vは使えません)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
▶貼り付けたらエンターキーを押下するとWeb UI(AUTOMATIC1111)のダウンロードと必要なフォルダの作成が進んでいきます。
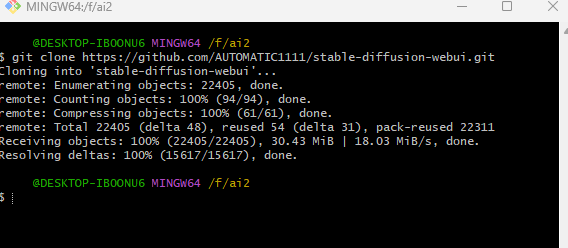
▶上の画像が表示されたら完了です。
1分もかからないと思います。
stable-diffusion webuiの最終設定
▶先ほど指定した場所に「stable-diffusion-webui」というフォルダが作られていますのでフォルダを開きます。
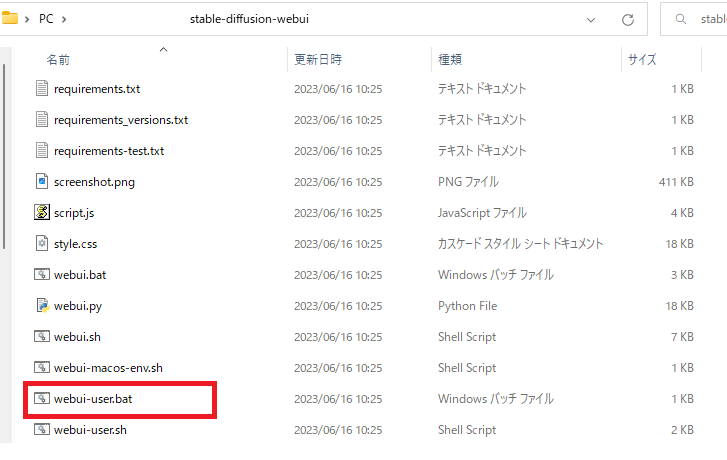
▶webui-user.batを実行します。
※拡張子を表示してない場合は、ファイルの種類で「Windowsバッチファイル」となっているファイルを実行してください。
▶コマンドプロンプトの画面が開き、引き続き必要なファイルのダウンロードが始まります。
ここは結構時間がかかります(数十分は見ておいた方が良いかも)

▶上の画像のところで止まっていれば完了となります。
これでAI画像を作るための基本的な準備が完了しました。
画像を作ってみる
webui-user.batの実行とブラウザでstable-diffusionの表示
▶webui-user.batを実行します。
先ほどの設定で使ったバッチファイルと同様です。
一例 D:stable-diffusion-webuiのフォルダ内の「webui-user.bat」を実行します。
起動に数十秒ほどかかると思います。下の画面が表示されたらOK。
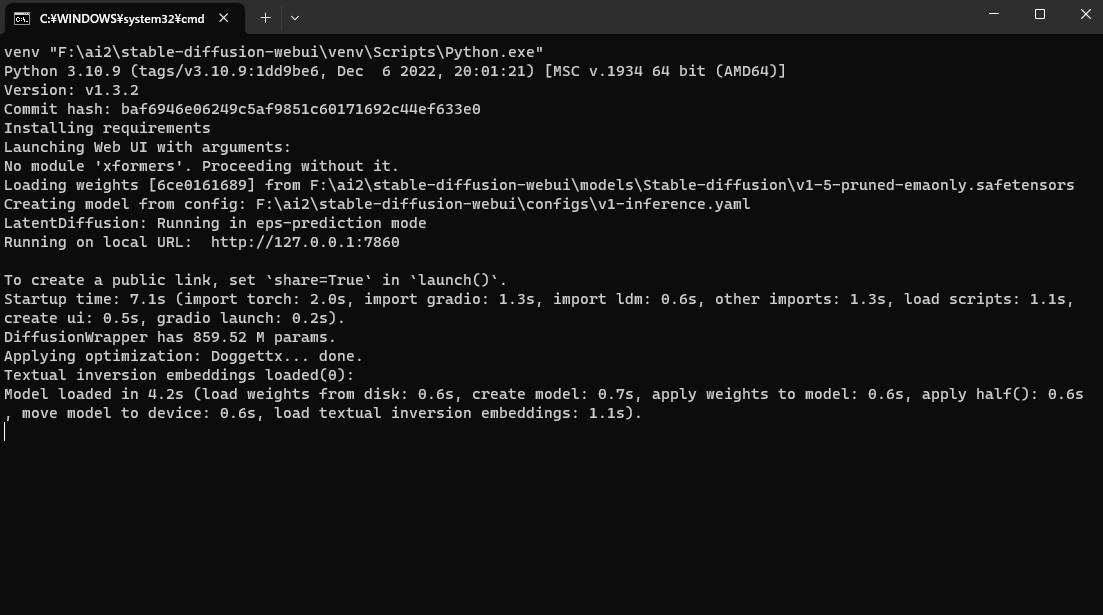
▶この画面の中にある「http://127.0.0.1:7860/]という記載のURLをCtrl+エンターで開くと標準のブラウザでstable-diffusion Web UIが開きます。
http://127.0.0.1:7860/ を自分の好きなブラウザに貼り付けて開くこともできます。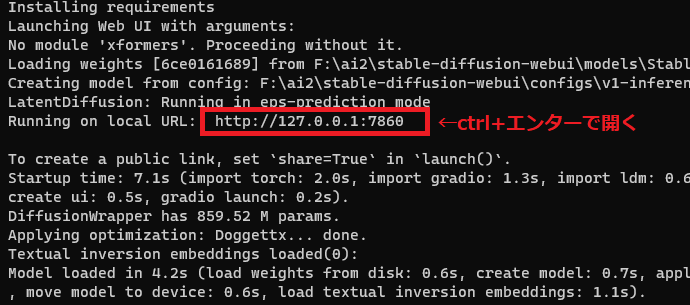
▶ブラウザでこの画面が表示されれば準備完了です。 ▶AI画像生成の際はwebui-user.batで開いたコマンドプロンプトの黒い画面は必ず起動したまま、閉じないようにしてください。
▶AI画像生成の際はwebui-user.batで開いたコマンドプロンプトの黒い画面は必ず起動したまま、閉じないようにしてください。
いよいよ画像の生成
いよいよ画像の生成です。
一番シンプルな方法を紹介します。
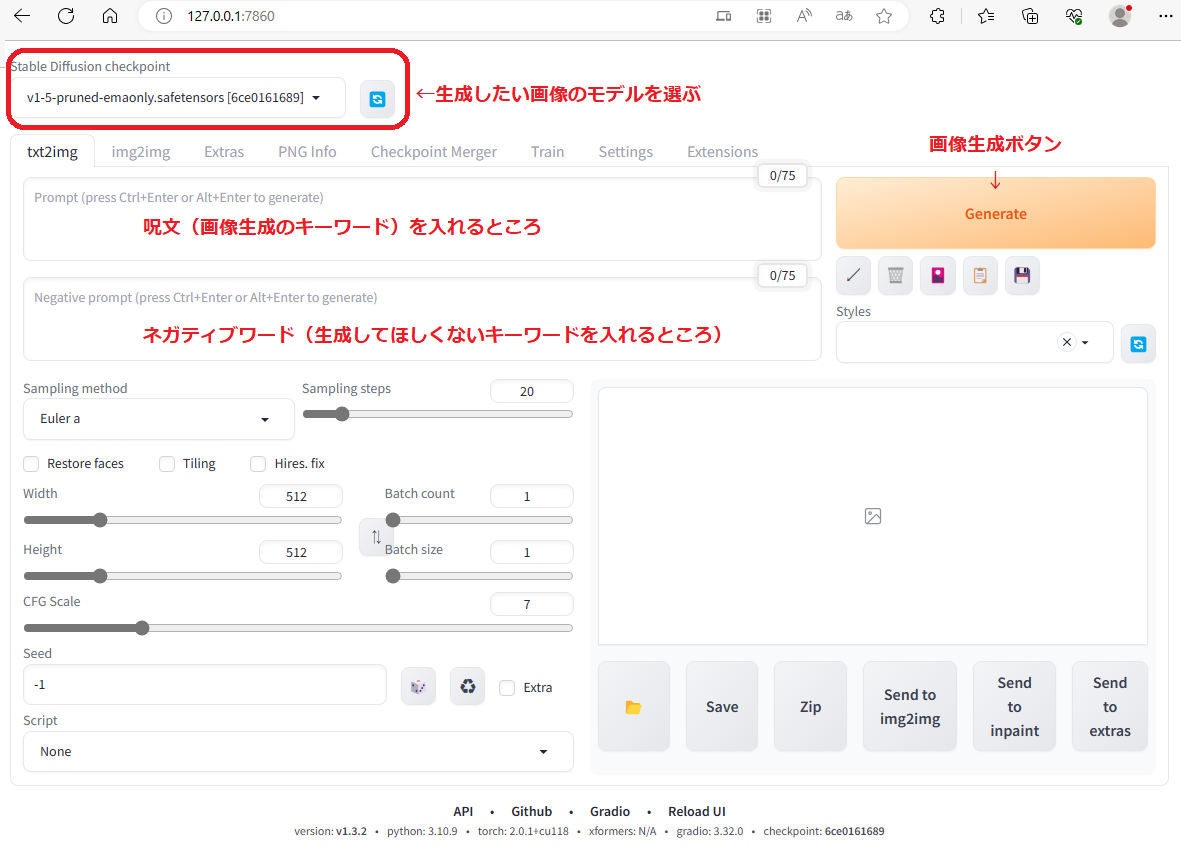
- 「Stable Diffusion checkpoint」で生成したい画像のモデルを選ぶ
- 「Prompt」に生成したい画像のキーワードを入力
- 「Negative prompt」に生成したくないキーワードを入力
- 「Generate」 で画像生成する
▶画像はメニュー画面の簡単な説明です。
というわけでまずは適当に、、
▶デフォルトで入っているモデル「v1-5-pruned-emaonly」を使って「girl」(女の子)を生成してみました。
※stable-diffusionでの入力はすべて英語になります。
girlだけで生成してみるとシンプルに女の子の画像が生成されました。
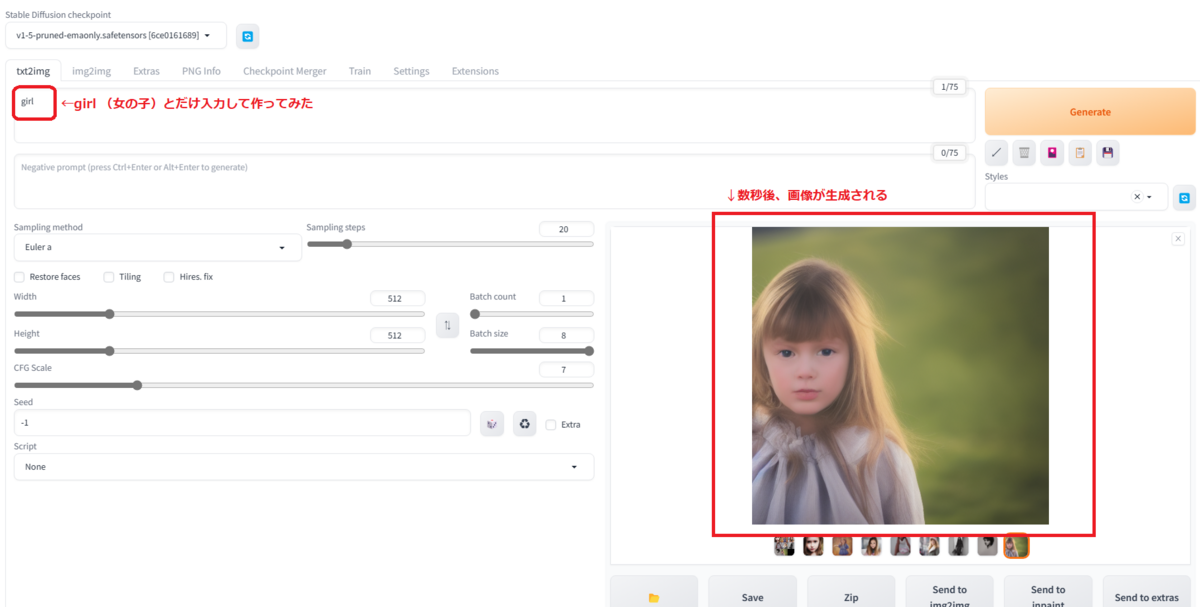
▶次はもう少し呪文(指示)を多めに出してみます。
prompt →
A beautiful Japanese girl is sitting in a cafe with a smile
(日本人の美しい女の子が笑顔でカフェで座っている)
RAW photo, best quality,realistic, photo-realistic, best quality,High quality texture,
(高いクオリティで、できるだけリアルに作ってねという指示です)
Negative→
「lowres, normal quality」(低品質や普通のクオリティは避けてね)
▶私は英語はさっぱりなので、呪文を作るときはすべてGoogle翻訳で作成しています。
▶その結果、こんな画像ができました。
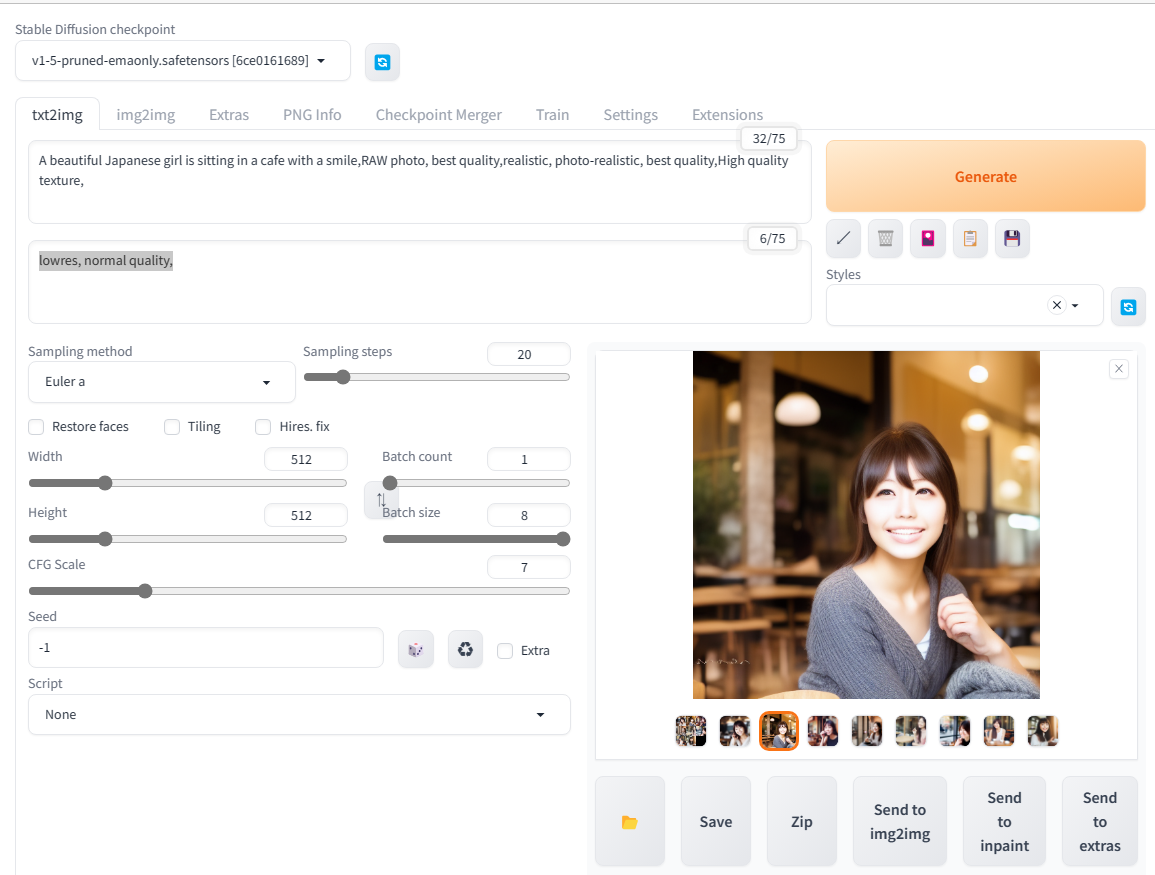
先ほどよりはクオリティ高い写真ができたと思います。
▶生成された画像は「\stable-diffusion-webui\outputs\txt2img-images\」に日付順で保存されています。
今回上の呪文を組み合わせてできた画像をいくつか紹介します。




比較的ましなものをアップしましたが、これを作るまでにとてもアップできないようなヤバイ画像(目が変だったり指が変だったり顔が崩れていたり)が次々と出来上がりました。今回はテストでシンプルな呪文での指示しか出していないのでそれも原因だったと思いますが一発で欲しい画像を出すというよりは何枚も何枚も生成してその中から気に入ったものを探すようなガチャを回しているようなイメージです。
今回はデフォルトで入っていた「v1-5-pruned-emaonly」というモデルを使用しましたが、モデルを追加して変更するとアニメ調になったり、もっとリアルな写真みたいな画像を作れたり、画像自体の雰囲気が大きく変わります。更に呪文をもっと細かく、色々な言葉を組み合わせを試して作りたい画像の最適解を探していくのが面白いですね。
他にも設定できる項目が山ほどあるのですが、この記事では画像ができたところまでのまとめと紹介までで終わりにして、また別記事に書いていきたいと思います。
長文お付き合いいただき、ありがとうございました。